
Захват флага — достаточно простой соревновательный режим, реализованный во многих популярных шутерах. У каждой команды есть некий маркер, расположенный на её базе, и цель состоит в том, чтобы захватить маркер соперников и успешно доставить его к себе. Однако то, что легко понимают люди, не так легко даётся машинам. Для захвата флага неигровые персонажи (боты) традиционно программируются с помощью эвристики и несложных алгоритмов, предоставляющих ограниченную свободу выбора и значительно уступающие людям. Но искусственный интеллект и машинное обучение обещают полностью перевернуть эту ситуацию.
В статье, опубликованной на этой неделе в журнале Science примерно через год после препринта, а также в своём блоге, исследователи из DeepMind, лондонской дочерней компании Alphabet, описывают систему, способную не только научиться играть в захват флага на картах Quake III Arena от id Software, но и разрабатывать совершенно новые командные стратегии, ни в чём не уступая человеку.

«Никто не рассказал ИИ, как играть в эту игру, у него был только результат — победил ИИ своего противника или нет. Прелесть использования подобного подхода в том, что вы никогда не знаете, какое поведение возникнет при обучении агентов», — рассказывает Макс Джадерберг (Max Jaderberg), научный сотрудник DeepMind, который ранее работал над системой машинного обучения AlphaStar (недавно она превзошла человеческую команду профессионалов в StarCraft II). Далее он объяснил, что ключевой метод их новой работы — это, во-первых, усиленное обучение, которое использует своеобразную систему наград для подталкивания программных агентов к выполнению поставленных целей, причём система наград работала независимо от того, выиграла команда ИИ или нет, а во-вторых, обучение агентов производилось в группах, что принуждало ИИ осваивать командное взаимодействие с самого начала.
«С исследовательской точки зрения это новинка для алгоритмического подхода, которая действительно впечатляет, — добавил Макс. — Способ, которым мы обучали наш ИИ, хорошо показывает, как масштабировать и реализовать некоторые классические эволюционные идеи».
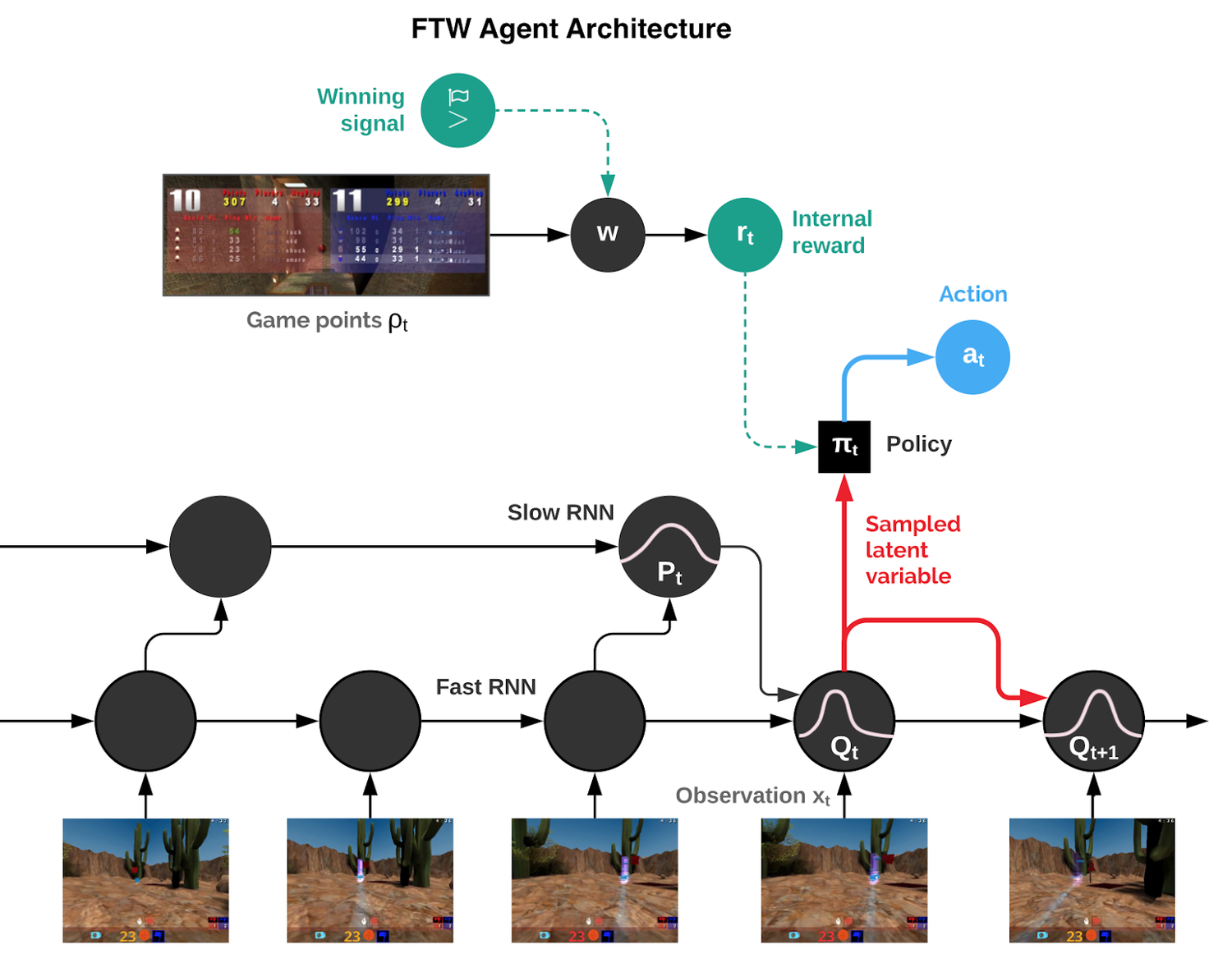
Агенты DeepMind, получившие вызывающее название — For The Win (FTW), учатся непосредственно на экранных пикселях, используя свёрточную нейронную сеть, набор математических функций (нейронов), расположенных в слоях, смоделированных по аналогии со зрительной корой мозга человека. Полученные данные передаются в две сети с многократной кратковременной памятью (англ. long short-term memory — LSTM), способные распознавать долгосрочные зависимости. Одна из них управляет оперативными данными с быстрой скоростью реакции, а другая работает медленно для анализа и формирования стратегий. Обе связаны с вариационной памятью, которую они совместно используют для прогнозирования изменений игрового мира и выполнения действий через эмулируемый игровой контроллер.

В общей сложности DeepMind обучила 30 агентов, учёные дали им ряд товарищей по команде и противников, с которыми можно было играть, а игровые карты выбирались случайным образом, чтобы ИИ не запоминал их. Каждый агент имел свой собственный сигнал вознаграждения, позволяющий ему создавать свои внутренние цели, например, захват флага. Каждый ИИ по отдельности сыграл около 450 тыс. игр на захват флага, что эквивалентно примерно четырём годам игрового опыта.
Полностью обученные агенты FTW научились применять стратегии, общие для любой карты, списка команд и их размеров. Они обучились человеческому поведению, такому как следование за товарищами по команде, размещение в лагере на базе противника и защита своей базы от нападающих, а также они постепенно утратили менее выгодные модели, например, слишком внимательное наблюдение за союзником.
Так каких же удалось добиться результатов? В турнире с участием 40 человек, в котором люди и агенты случайным образом играли как вместе, так и друг против друга, агенты FTW значительно превзошли коэффициент побед у игроков-людей. Рейтинг Эло, который соответствует вероятности выигрыша, у ИИ составил 1600, по сравнению с 1300 у «сильных» игроков-людей и 1050 у «среднего» игрока-человека.
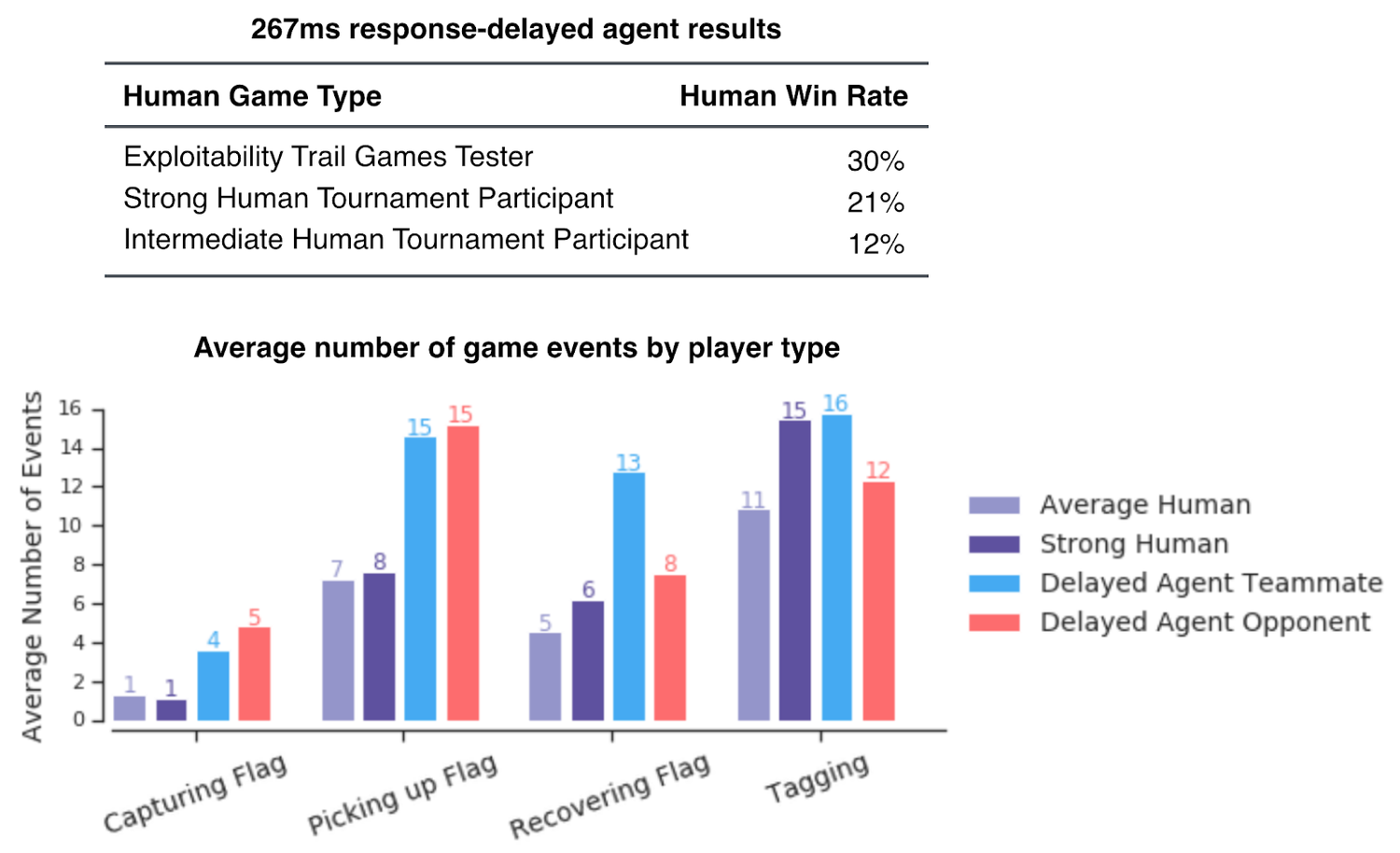
Это не удивительно, так как скорость реакции ИИ значительно выше, чем у человека, что давало первому значимое преимущество в первоначальных экспериментах. Но даже когда точность агентов была уменьшена, а время реакции увеличено благодаря встроенной задержке в 257 миллисекунд, ИИ всё равно превзошёл людей. Продвинутые и обычные игроки выиграли только 21 % и 12 % игр от общего числа соответственно.
Более того, после публикации исследования учёные решили испытать агентов на полноценных картах Quake III Arena со сложной архитектурой уровней и дополнительным объектами, таких как Future Crossings и Ironwood, где ИИ начал успешно оспаривать первенство людей в тестовых матчах. Когда исследователи изучили схемы активации нейронных сетей у агентов, то есть функции нейронов, ответственных за определение выходных данных на основе входящей информации, они обнаружили кластеры, представляющие собой комнаты, состояние флагов, видимость товарищей по команде и противников, присутствие или отсутствие агентов на базе противника или на базе команды, и другие значимые аспекты игрового процесса. Обученные агенты даже содержали нейроны, которые кодировали непосредственно конкретные ситуации, например, когда флаг взят агентом или когда его держит союзник.
«Я думаю, что одна из вещей, на которые стоит обратить внимание, заключается в том, что эти многоагентные команды являются исключительно мощными, и наше исследование демонстрирует это, — говорит Джадерберг. — Это то, что мы учимся делать лучше и лучше за последние несколько лет — как решить проблему обучения с подкреплением. И усиленное обучение действительно показало себя блестяще».
Тор Грэпел (Thore Graepel), профессор компьютерных наук в Университетском колледже Лондона и ученый из DeepMind, уверен, что их работа подчёркивает потенциал многоагентного обучения для развития ИИ в будущем. Также она может послужить основой для исследований взаимодействия человека с машиной и систем, которые дополняют друг друга или работают вместе.
«Наши результаты показывают, что многоагентное обучение с подкреплением может успешно освоить сложную игру до такой степени, что игроки-люди даже приходят к мнению, что компьютерные игроки — лучшие товарищи по команде. Исследование также предоставляет крайне интересный углубленный анализ того, как обученные агенты ведут себя и работают вместе, — рассказывает Грэпел. — Что делает эти результаты такими захватывающими, так это то, что эти агенты воспринимают своё окружение от первого лица, [то есть] так же, как человек-игрок. Чтобы научиться играть тактически и сотрудничать со своими товарищами по команде, эти агенты должны были полагаться на обратную связь с результатами игры, без какого-либо учителя или тренера, показывающего им, что нужно делать».